Playing with BGP graceful restart on SRX
Have you ever wanted to do a transparent failover with Juniper SRX cluster firewalls? When the redundancy group 0 switch from one box to the other, the route-engine has to be restarted and all the dynamic routing protocols have to be restarted. Usually this means huge impact on the traffic…
Graceful restart is a feature designed exactly to avoid this. When enabled, the firewall (or router in this case) keeps the dynamically learned routes into forwarding table until the route-engine and the dynamic protocols are restarted. Graceful restart must be enabled on all the devices to work properly. If, for whatever reason, the route-engine or the protocol fail to restart, there is a timer after which the neighbouring router flushes the routes from their forwarding tables to avoid blackholing traffic.
The test setup is very simple, one router, one firewall cluster, one device to ping through the firewall cluster from the router.
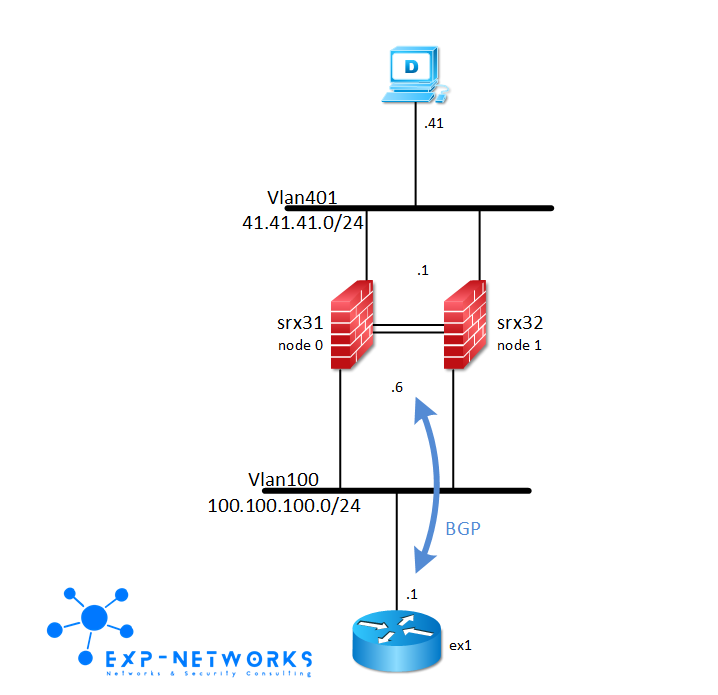
Let’s test a failover without graceful-restart first.
routing-options {
autonomous-system 65000;
}
protocols {
bgp {
export CON2BGP;
inactive: graceful-restart;
group EX {
type internal;
neighbor 100.100.100.1;
}
}
}Ping from the router while executing the command “request chassis cluster failover redundancy-group 0 node 1”.
{master:0}
root@ex1> ping 41.41.41.41 interval 0.1 count 10000000
PING 41.41.41.41 (41.41.41.41): 56 data bytes
64 bytes from 41.41.41.41: icmp_seq=0 ttl=63 time=4.021 ms
64 bytes from 41.41.41.41: icmp_seq=1 ttl=63 time=1.654 ms
(...)
64 bytes from 41.41.41.41: icmp_seq=241 ttl=63 time=1.739 ms
64 bytes from 41.41.41.41: icmp_seq=242 ttl=63 time=4.399 ms
ping: sendto: No route to host ^
ping: sendto: No route to host |
(...) 17.4s
ping: sendto: No route to host |
ping: sendto: No route to host v
64 bytes from 41.41.41.41: icmp_seq=416 ttl=63 time=1.580 ms
64 bytes from 41.41.41.41: icmp_seq=417 ttl=63 time=1.477 ms
Traffic has been interrupted for 17.4s… An eternity in a decent network.
Now, let’s enable BGP graceful restart on the firewalls and on the router. As you can see it is pretty straightforward.
set routing-options graceful-restart set protocols bgp graceful-restart
Let’s do the same ping test again.
{master:0}
root@ex1> ping 41.41.41.41 interval 0.1 count 10000000
PING 41.41.41.41 (41.41.41.41): 56 data bytes
64 bytes from 41.41.41.41: icmp_seq=0 ttl=63 time=4.729 ms
64 bytes from 41.41.41.41: icmp_seq=1 ttl=63 time=4.436 ms
(...)
64 bytes from 41.41.41.41: icmp_seq=1789 ttl=63 time=4.403 ms
64 bytes from 41.41.41.41: icmp_seq=1790 ttl=63 time=8.459 ms
This time, there is no visible impact!
During the route-engine restart, on the facing router you can see the route is going to “stale” status. This means the route is kept in the forwarding table during the BGP restart on the firewalls.
{master:0}
root@ex1> show route 41.41.41.0 table inet.0 detail
inet.0: 13 destinations, 16 routes (13 active, 0 holddown, 0 hidden)
Restart Complete
41.41.41.0/24 (1 entry, 1 announced)
*BGP Preference: 170/-101
Next hop type: Indirect
Next-hop reference count: 3
Source: 100.100.100.6
Next hop type: Router, Next hop index: 1414
Next hop: 100.100.100.6 via vlan.100, selected
Protocol next hop: 100.100.100.6
Indirect next hop: 284f4b0 131073
State: <Active Int Ext>
Local AS: 65000 Peer AS: 65000
Age: 3:41 Metric2: 0
Task: BGP_65000.100.100.100.6
Announcement bits (3): 0-KRT 1-BGP RT Background 2-Resolve tree 1
AS path: I
Stale Accepted
Localpref: 100
Router ID: 41.41.41.1
You can also see on the neighbour details that graceful restart is enabled
{master:0}
root@ex1> show bgp neighbor 100.100.100.6
Peer: 100.100.100.6+57493 AS 65000 Local: 100.100.100.1+179 AS 65000
Type: Internal State: Established (route reflector client)Flags:
Last State: OpenConfirm Last Event: RecvKeepAlive
Last Error: None
Export: [ CON2BGP ]
Options:
Address families configured: inet-unicast inet6-unicast
Holdtime: 90 Preference: 170
Number of flaps: 3
Last flap event: Restart
Error: 'Cease' Sent: 0 Recv: 1
Peer ID: 41.41.41.1 Local ID: 1.1.1.1 Active Holdtime: 90
Keepalive Interval: 30 Peer index: 2
BFD: disabled, down
NLRI for restart configured on peer: inet-unicast inet6-unicast
NLRI advertised by peer: inet-unicast
NLRI for this session: inet-unicast
Peer supports Refresh capability (2)
Restart time configured on the peer: 120
Stale routes from peer are kept for: 300
Restart time requested by this peer: 120
Restart flag received from the peer: Restarting
NLRI that peer supports restart for: inet-unicast
NLRI peer can save forwarding state: inet-unicast
NLRI that peer saved forwarding for: inet-unicast
NLRI that restart is negotiated for: inet-unicast
NLRI of received end-of-rib markers: inet-unicast
NLRI of all end-of-rib markers sent: inet-unicast
Peer supports 4 byte AS extension (peer-as 65000)
Peer does not support Addpath
Table inet.0 Bit: 10000
RIB State: BGP restart is complete
Send state: in sync
Active prefixes: 1
Received prefixes: 1
Accepted prefixes: 1
Suppressed due to damping: 0
Advertised prefixes: 5
Last traffic (seconds): Received 1 Sent 8 Checked 14
Input messages: Total 11 Updates 2 Refreshes 0 Octets 286
Output messages: Total 14 Updates 5 Refreshes 0 Octets 534
Output Queue[0]: 0
As you can see, enabling graceful-restart is very easy to configure and can reduce dramatically the downtime in your network… So do not hesitate to activate it!