HA Load-balancing with IP Anycast
Nowadays, having a load-balancer in datacenters is more and more crucial not only to assure an easy scalability but also to assure high availability (HA). If properly configured, the load-balancer will be able to detect a failed application server, will remove it from its resource pool and will eventually reassign clients to other available servers.
Now, the load-balancer should not become the single point of failure, that’s why most of the vendor propose clustered load-balancers where one node is in hot standby mode waiting for the opportunity to take over the traffic handled by its active peer. But what happen if you have two datacenters? Stretched cluster across the two DC would need stretched L2 domain which is definitely not a good idea…
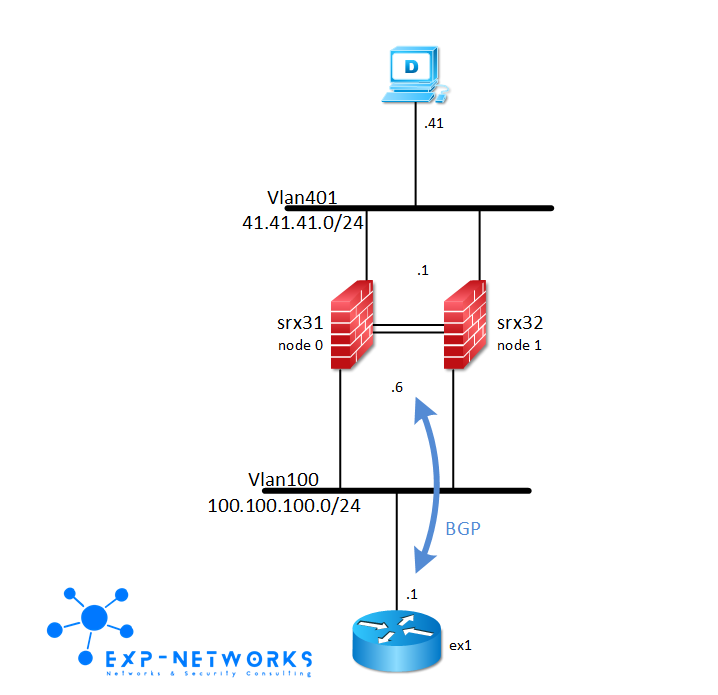
High end load-balancers like Cisco’s ACE or F5′s LTM can influence the IP routing to attract the traffic for a particular VIP. Cisco’s ACE is able to inject static routes on the Supervisor’s MSFC when a VIP is considered operational. F5′s LTM can do almost the same by running BGP. Let see how it can help to meet cross datacenter HA
Client to load-balancer
The main goal is to avoid the client to have to take any action in case of failure. We will then use the same VIP in both datacenters and let the IP routing protocol decide to which load-balancer a particular client will go. This principle is known as Anycasting, the client goes always to the closest load-balancer from a routing point of view. The trick here is to make sure the client will always go to the same load-balancer for a given session, this require a properly set IGP metric to avoid route load-balancing between the two load-balancers from anywhere in the network.
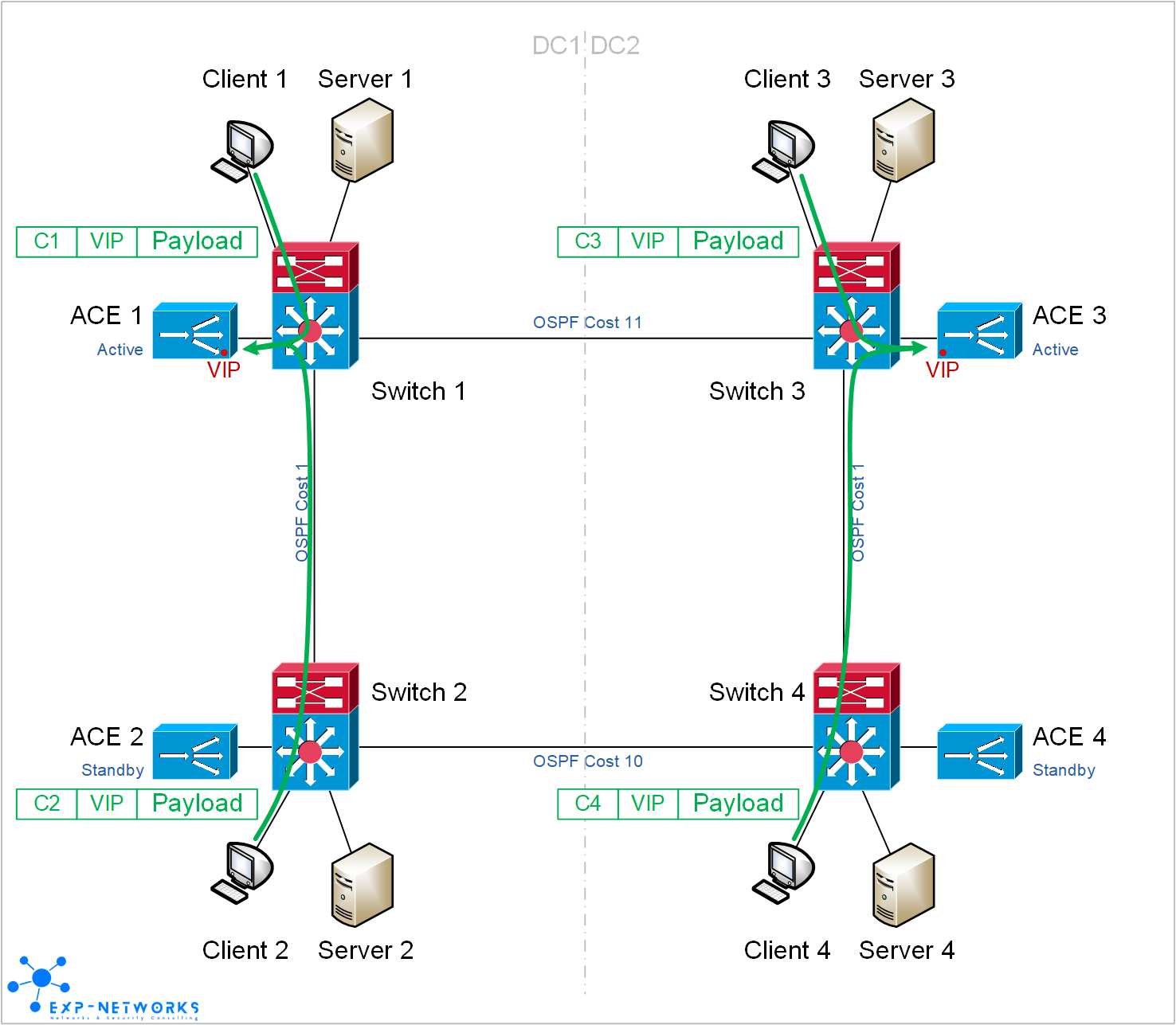
In a steady state, Client 1 and Client 2 are always going to ACE 1, Client 3 and Client 4 are always going to ACE 3 even though they are all using the same VIP.
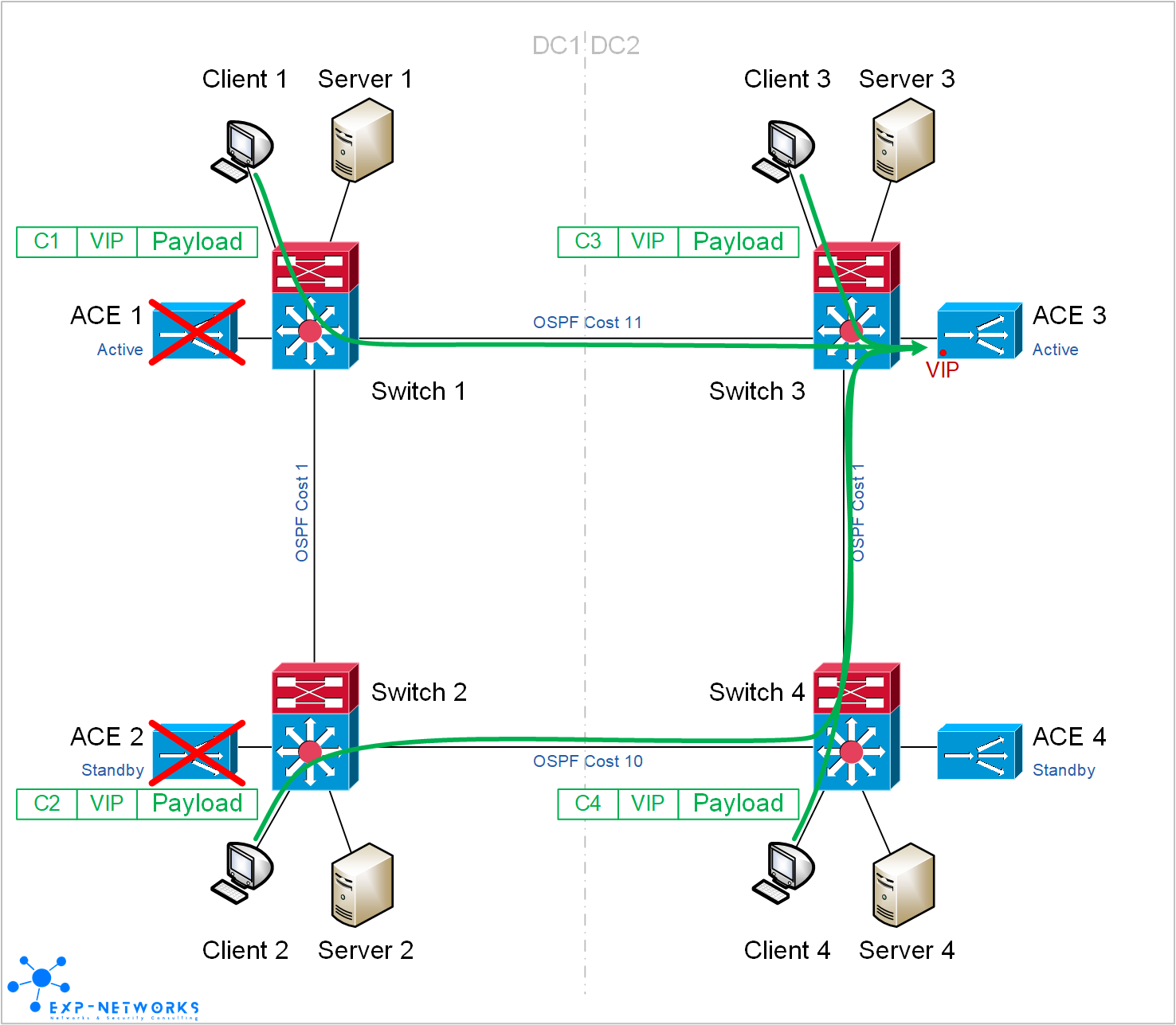
In case of failure of both ACE in DC1, Client 1 and Client 2 are redirected to the ACE in DC2 by the IGP.
Failure of ACE 1 only would trigger a local failover to ACE 2. In that case, there are no impact at all on the flows.
Load-balancer to application servers
We have to make sure the application servers will always respond to the load-balancer who has initiated the connection regardless to the server location in the network. This is achieved by using different NAT pool for each load-balancers. That way, the application servers “know” which ACE has initiated a particular session.
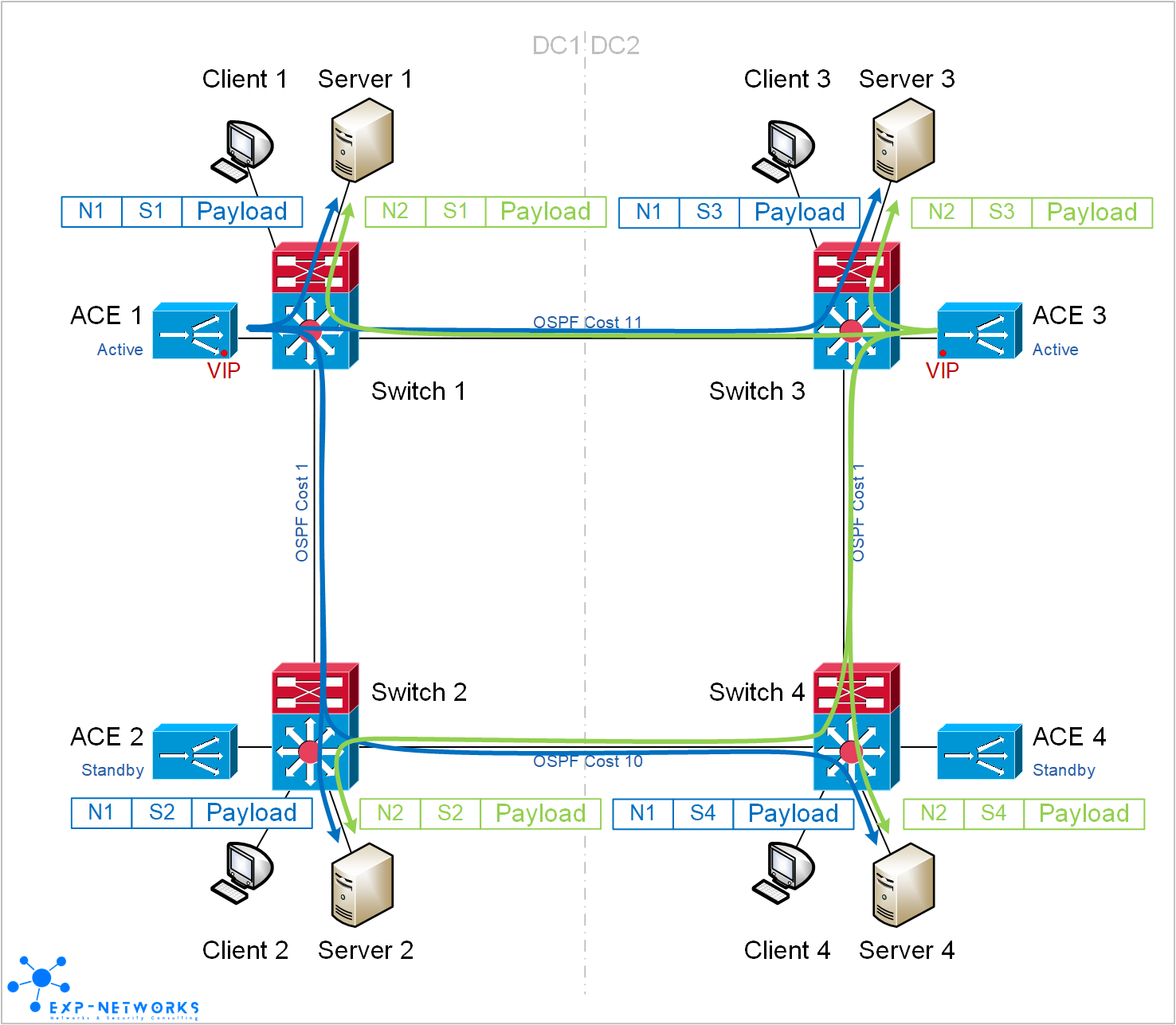
Sessions initiated by ACE 1 (or ACE 2) are using N1 as source IP while sessions initiated by ACE 3 (or ACE 4) are sourced from N2 IP.
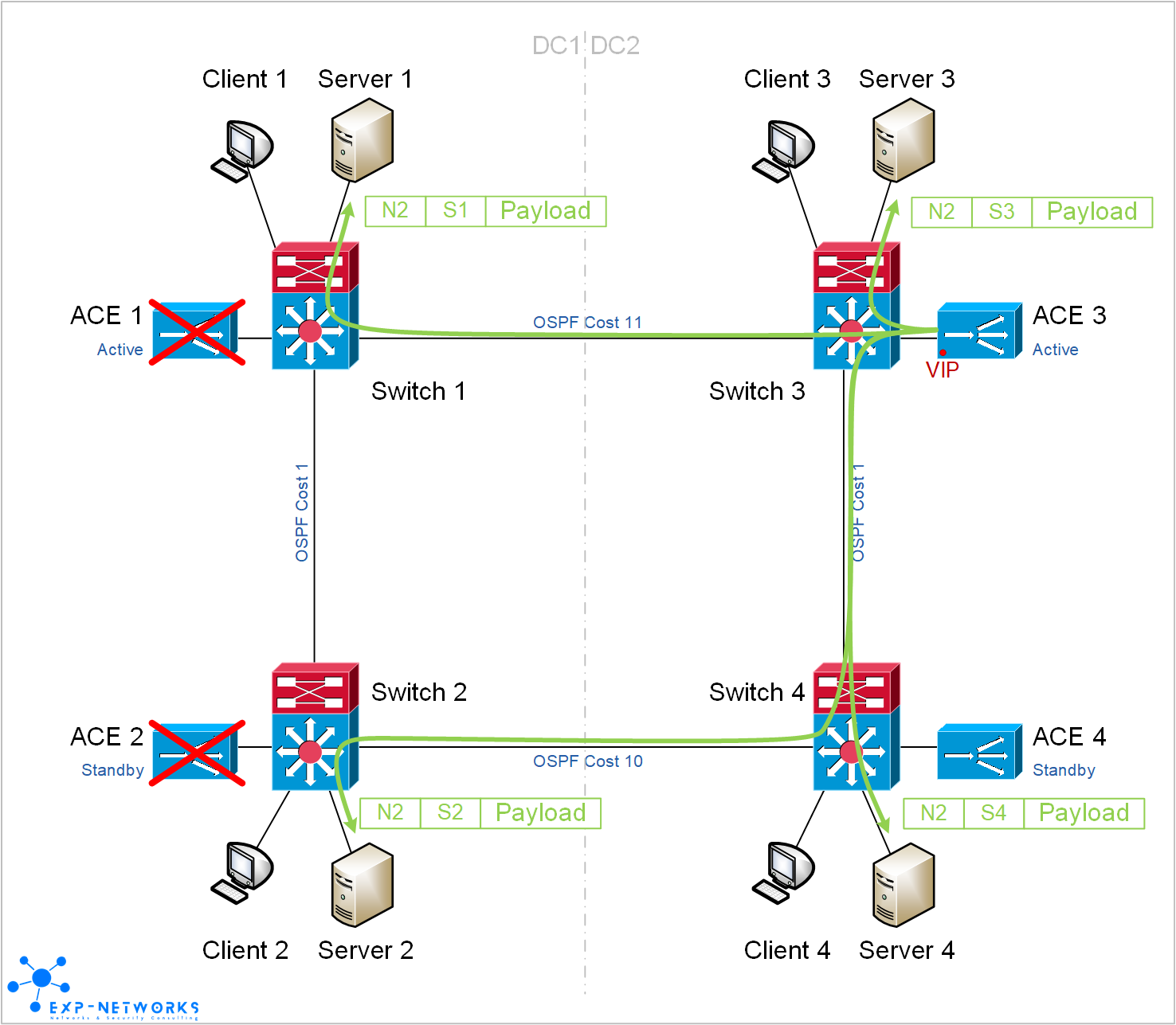
In case of failure of both ACE in DC1, all flows going through ACE 3 are not affected at all. Sessions going through ACE 1 / ACE 2 would need to be restarted.
Conclusion
With this kind of setup, the challenge reside in the ACE configuration. The two clusters configuration must be aligned but it won’t be done automagically… Network administrator has to be very cautious…
Another approach is the use of intelligent DNS like Cisco’s GSS or F5′s 3DNS but it isn’t in the scope of this post.
Thanks to leave a small comment if you like or if you don’t like… You may also ‘+1′ if you like.